
CHUHACKS #3 – Detectando temas calientes en tu nicho
 ¡Jeloooooooooooou! Chuisete por aquí, continuamos con los chuhacks, esta vez el number zri (número 3, zi no sabez ingléz).
¡Jeloooooooooooou! Chuisete por aquí, continuamos con los chuhacks, esta vez el number zri (número 3, zi no sabez ingléz).
Hoy os voy a hacer un curso rápido e intensivo de scraping centrado en localizar los temas más «calientes» de cualquier blog. Esto es útil para comenzar un nuevo proyecto y saber qué temas generan más comentarios y por tanto son temas que podríamos tratar o tener en cuenta.
Esto se puede aplicar a cualquier tipo de blog, web o foro si se tienen los conocimientos adecuados, pero en este caso lo haremos sobre un blog (el mío) y de forma muy sencilla.
Scrapeando comentarios en un blog
Vamos a instalar la extensión WebScraper (un scraper que funciona sobre el propio navegador de Chrome) y abrimos la web que queremos espiar, en este caso Chuiso.com. Como vamos a hacerlo de la forma más simple posible, evitaremos el scraping navegando por la paginación y nos centraremos en la estructura de las URLs. Iremos a la última página y veremos que en un blog WordPress la estructura es muy sencilla:

Si queremos que nuestro scraper viaje de la página 1 a la página 29 (la última) debemos crear esta URL:
https://chuiso.com/page/[1-29]/
Con [1-29] recorrerá todas las cifras entre ambos números. Así que pulsamos F12 para abrir la consola y vamos a la nueva sección: WebScraper. Le damos a crear un nuevo sitemap, le ponemos un nombre y añadimos nuestra URL:
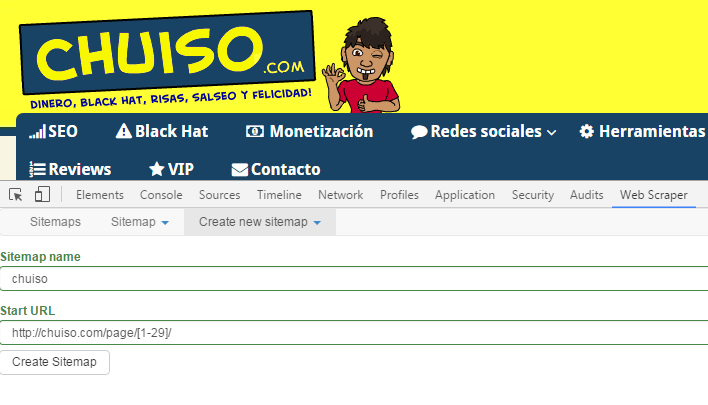
Dentro de este nuevo proyecto crearemos un nuevo selector dando a «Add new selector». Le ponemos un nombre cualquiera y seleccionamos el tipo «link». Le daremos a «select», «multiple» y seleccionaremos al menos 2 veces el link que enlaza a los comentarios de cada artículo, de este modo detectará el patrón y marcará en rojo todos los elementos similares:

Salvamos el selector y listo. Ahora podríamos hacer exactamente lo mismo con el resto de objetos que queramos scrapear, como por ejemplo el título (como text) u otros datos como las interacciones sociales, categorías, etc.
Se puede scrapear de todo, pero para este chuhack vamos a lo simple, ya que el arte del scraping da mucho de sí, que se lo digan a mi compi VayaSEO.
Nos vamos a la sección de Sitemap > Scrape > Start scraping y esperamos a que acabe. Luego nos vamos a «Export data as CSV» y veremos que ha extraído algo así:
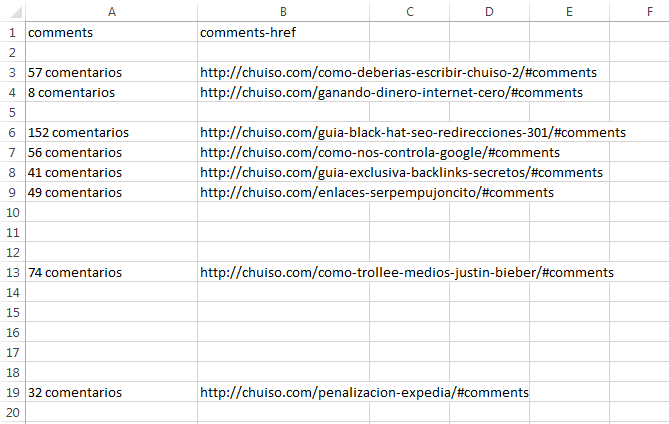
Con la herramienta de reemplazar limpiamos (sin comillas):
- » comentarios»
- » comentario»
- «#comments»
Y acto seguido ordenamos de mayor a menor, finalmente nos queda lo que tanto deseamos:

De un vistazo se puede apreciar qué tipo de contenidos generaron más respuesta por parte de los usuarios, y repitiendo este proceso con varios blogs grandes de tu sector se puede extraer suficiente información para crear una estrategia de contenidos exitosa.
Por supuesto el verdadero potencial de este chuhack es aprender nociones básicas del arte del scraping 😉
Hasta aquí el chuhack de hoy 😛






Zas!!! Otro hack buenísimo para averiguar cositas, muy util cuando no tienes ni idea de que escribir.
Como siempre Chuiso muy top ayudando a los demás.
Saludos!!
Mola un cojón, ademas se puede combinar con otro script que temeta los datos en una base de datos y con eso ya puedes hacer mixes que flipas!
Excelente Chuhacks!
Gracias!
Qué bueno eres, mamón :*
Le voy a dar caña al plugin, por que me están ocurriendo algunas maldades.
Increíble muy útil por el momento no me sirve ya que es una pagina que ofrece servicios, Sigue así amigo.
Buen Artículo, pepón. 😀
No conocía la extensión de Chrome, que acabo de instalar. Pondré en práctica tus conocimientos. Gracias por compartir.
Magnifico, muy buen tip. Pero sobre todo para hacer lo que tu recomiendas, pensar fuera del tiesto y usar la técnica para nuevas ideas. Lo acabo de usar para extrear de una web que concede una especie de sello de acreditación, sacar todas las url que lo tienen y ahora a ver si….. se me ocurren varias cosas.
Saludos
asopotamadre D:, muchas gracias por compartir!!
perfect!
Hombre pero para saber lo que se comenta más hay por hay webs y cosas que hacen eso en auto, pero gracias por la idea.
¿Por qué a mí no me salen las opciones de sitemap y nuevo sitemap cuando abro la extensión Web Scraper? Me salen ID, Start URL y actions. Gracias.
Qué pavo soy copón! Olvidaos de la memez que acabo de preguntar 🙂
Hola chuiso. Y para un blogspot cual seria la estructura del link? (https://chuiso.com/page/%5B1-29%5D/). Saludos! 😀
Pues habría que ver como es la URL y detectar las cifras que van modificándose.
Hola Chuiso, fenomenal blog post. Me ha surgido una duda, ¿como aplicar esta tecnica por ejemplo en un periódico, donde el enlace no contiene necesariamente una descripción de lo que hay dentro?
O en un foro, para sacar 3 columnas: titulo del post, visitas y respuestas. He conseguido hacer la extracción pero los datos salen desordenados y no casan 🙁
¿es posible hacer esto?
Ufff, habría que verlo, ya que cada caso es distinto a la hora de hacer scraping.